Alexander
Levin-Koopman

As a lecturer in Applied Data Science at the University of Michigan School of Information, I'm passionate about solving problems through insights extracted from complex data sets. With a Master's degree in Applied Data Science (4.0 GPA) from the University of Michigan and a Bachelor's degree in Mathematics from the University of Colorado at Boulder, I've developed a strong foundation in statistical analysis, machine learning, and data visualization.
My academic background has equipped me with a unique ability to approach problems from multiple angles, think creatively, and communicate complex ideas effectively. While my experience is rooted in academia, I'm eager to apply my skills in a real-world setting and drive business outcomes through data-driven decision making.
I thrive on solving intricate problems and uncovering hidden patterns in data. My goal is to leverage my expertise to inform strategic decisions, optimize processes, and create value for organizations. If you're looking for a driven and analytical problem-solver who is passionate about data science, let's connect!
View My LinkedIn Profile
View My GitHub Profile
Hosted on GitHub Pages — Theme by orderedlist
Topic Analysis and Word2Vec Model of the Yelp Dataset
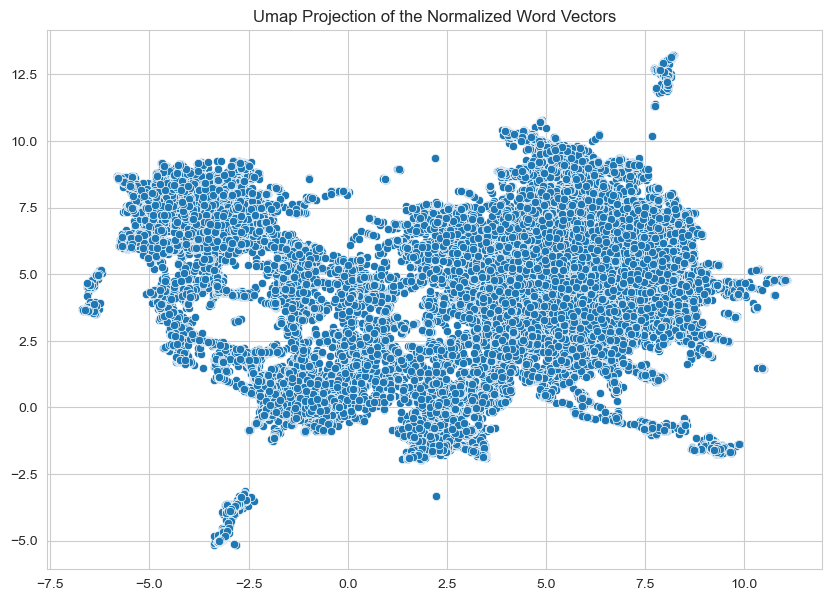
Project description: There are four major steps that make up this project. The first was preprocessing the data using spaCy, this included tokenization, lemmatization, punctuation removal and named entity recognition. Next was the phrase modeling step using gensim, creating bigrams and trigrams from the cleaned unigram text. Then we turn to the modeling phase, where we first focused on the finding the optimal number of topics for extraction, the results of which are shown in Figure 1. In this case we landed on 30 topics to use in the gensim LDA model on the full dataset. Figure 2 shows the resulting topics and terms (best seen interactively). Finally A gensim Word2Vec model was trained on the full corpus of 41 million sentences, to find semantic similarity and vector embedding space relationships of terms. This can be seen in Figure 3 (also best seen interactively).
Preprocessing Code | Preprocessing Analysis
Figure 1: Search Optimal Number of Topics
Search Code | Search Results and Analysis
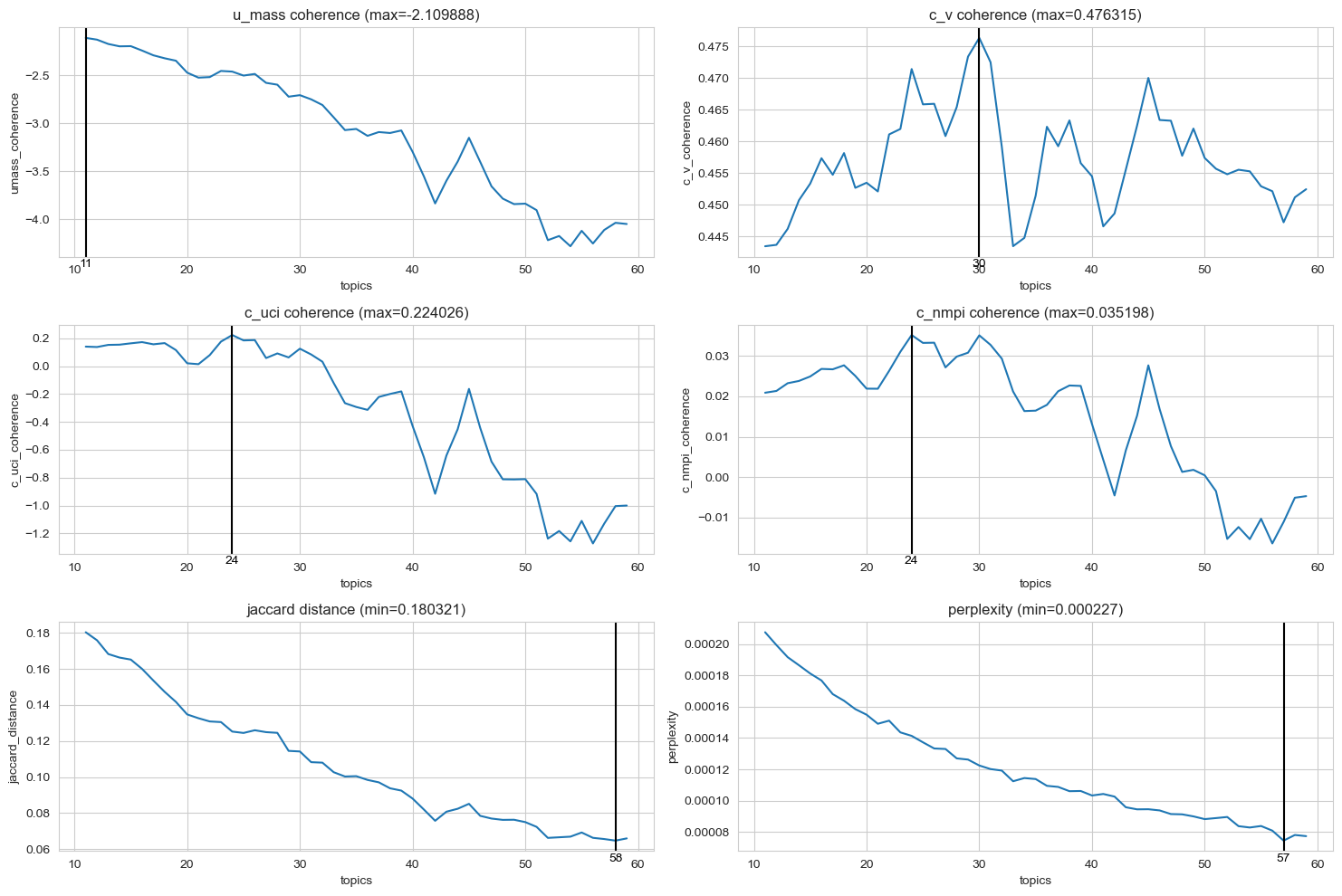
Figure 2: Visualization of the Extracted topics using pyLDAvis
LDA Model Training Code | LDA Model Analysis
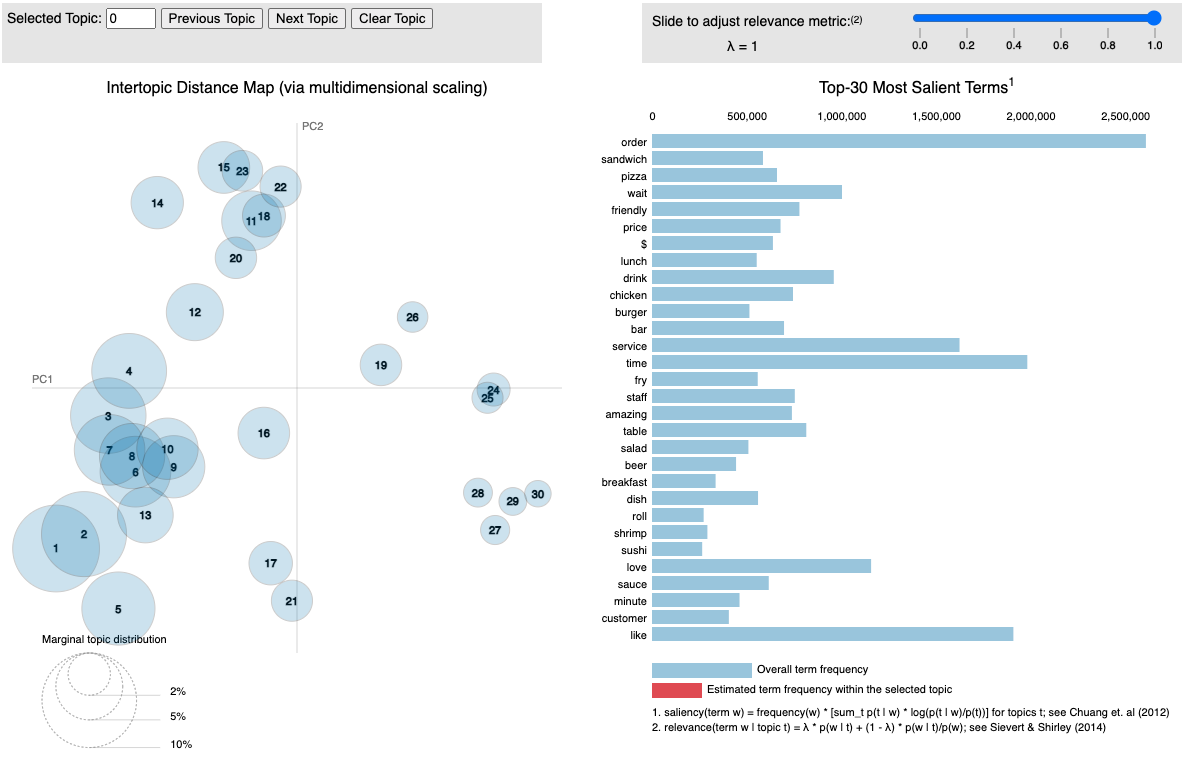
Figure 3: Word2Vec Embedding
Word2Vec Training Code | Word2Vec Inspection and Analysis